1. 引出IO多路复用
为什么 Redis 中要使用 I/O 多路复用这种技术呢?
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
要弄清问题先要知道问题的出现原因
由于进程的执行过程是线性的(也就是顺序执行),当我们调用低速系统I/O(read,write,accept等等),进程可能阻塞,此时进程就阻塞在这个调用上,不能执行其他操作。阻塞很正常, 接下来考虑这么一个问题:一个服务器进程和一个客户端进程通信,服务器端read(sockfd1,bud,bufsize),此时客户端进程没有发送数据,那么read(阻塞调用)将阻塞直到客户端write(sockfd,but,size)发来数据。在一个客户和服务器通信时这没什么问题,当多个客户与服务器通信时,若服务器阻塞于其中一个客sockfd1,当另一个客户的数据到达套接字sockfd2时,服务器仍不能处理,仍然阻塞在read(sockfd1,...)上。此时问题就出现了,不能及时处理另一个客户的服务,肿么办?I/O多路复用来解决!
继续上面的问题,有多个客户连接,sockfd1、sockfd2、sockfd3..sockfdn同时监听这n个客户,当其中有一个发来消息时就从select的阻塞中返回,然后就调用read读取收到消息的sockfd,然后又循环回select阻塞;这样就不会因为阻塞在其中一个上而不能处理另一个客户的消息。
Q: 那这样子,在读取socket1的数据时,如果其它socket有数据来,那么也要等到socket1读取完了才能继续读取其它socket的数据吧。那不是也阻塞住了吗?而且读取到的数据也要开启线程处理吧,那这和多线程I/O有什么区别呢?
A:
CPU本来就是线性的,不论什么都需要顺序处理,并行只能是多核CPU。
I/O多路复用本来就是用来解决对多个I/O监听时,一个I/O阻塞影响其他I/O的问题,跟多线程没关系。
跟多线程相比较,线程切换需要切换到内核进行线程切换,需要消耗时间和资源。而I/O多路复用不需要切换线/进程,效率相对较高,特别是对高并发的应用nginx就是用I/O多路复用,故而性能极佳。但多线程编程逻辑和处理上比I/O多路复用简单,而I/O多路复用处理起来较为复杂。
2. 理解IO多路复用
2.1. 什么是I/O多路复用
I/O 多路复用其实是在单个线程中通过记录跟踪每一个sock(I/O流) 的状态来管理多个I/O流。结合下图可以清晰地理解I/O多路复用。
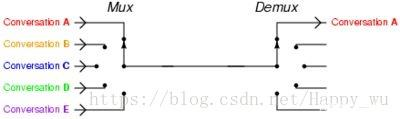
select, poll, epoll 都是I/O多路复用的具体的实现。epoll性能比其他几者要好。redis中的I/O多路复用的所有功能通过包装常见的select、epoll、evport和kqueue这些I/O多路复用函数库来实现的。
2.2. 多路分离函数select
IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。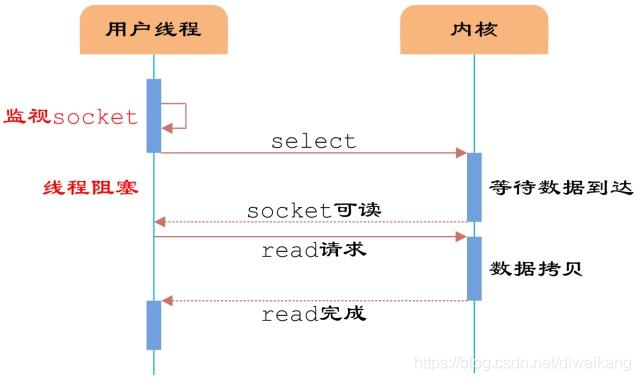
如上图所示,用户线程发起请求的时候,首先会将socket添加到select中,这时阻塞等待select函数返回。当数据到达时,select被激活,select函数返回,此时用户线程才正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行I/O请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的I/O请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个I/O请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
2.3. Reactor(反应器模式)
如上图,I/O多路复用模型使用了Reactor设计模式实现了这一机制。通过Reactor的方式,可以将用户线程轮询I/O操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路I/O复用模型也被称为异步阻塞I/O模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用I/O多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起I/O请求时,数据已经到达了,用户线程一定不会被阻塞。
3. 总结
I/O 多路复用模型是利用select、poll、epoll可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll是只轮询那些真正发出了事件的流),依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。